
Tables created in word processing programs often use merged cells to group values. These cells can cause trouble when we want to work with the data in a programming context, regardless of how the tables were shared (.doc, .docx, PDF).
In R, we can get the data from Word files and PDFs into data frames thanks to packages such as docxtractr, PDFtools, tablulizer, and others (or even AI tools apparently), often preserving the original lines and structure which we can then wrangle into something usable.
This post shows a brief walkthrough for cleaning this type of table, based on my experience with real documents and showcasing a new helper function added to the unheadr package for version 0.4.0 (now on CRAN).
This example is based on publicly available data with information on income, property and property obligations for government officials in the Chukotka Autonomous Okrug, which is the easternmost federal subject of Russia.
Various examples can be downloaded here:
The files look like this, some are available as Word documents and some as PDFs.
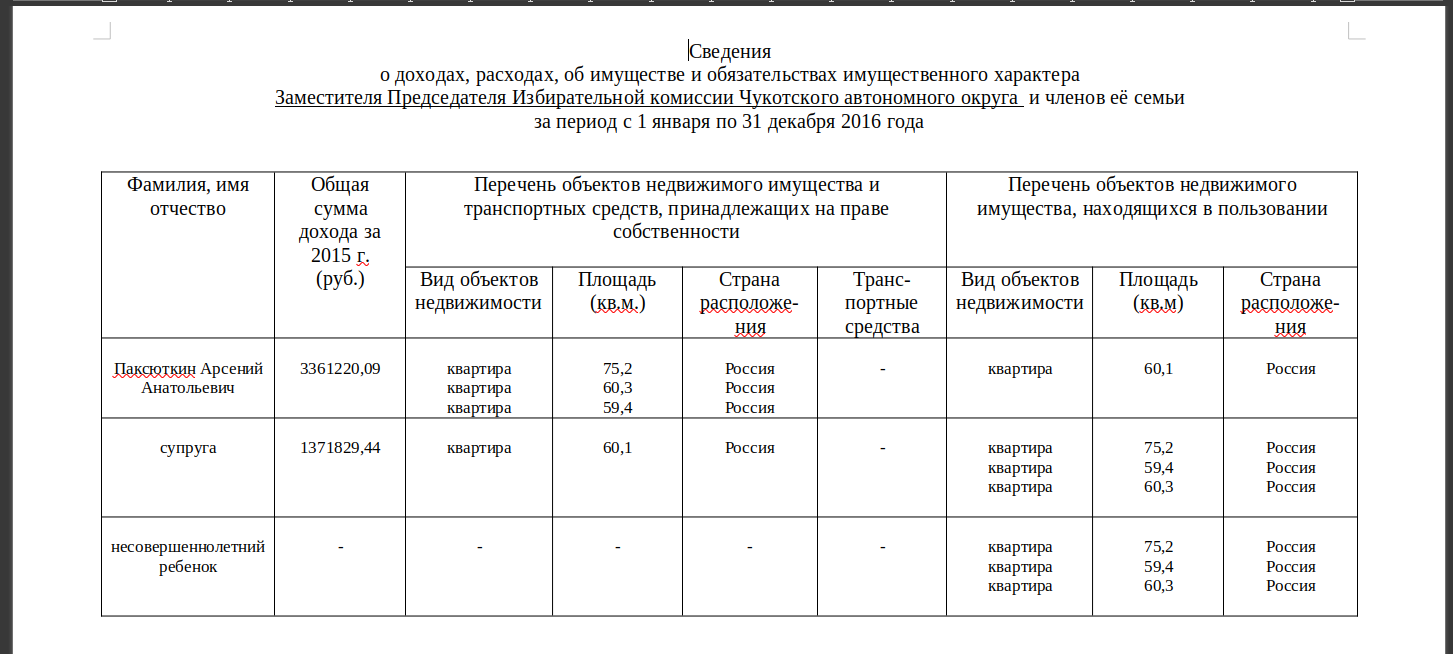
For this example, a translated and simplified version looks like this:
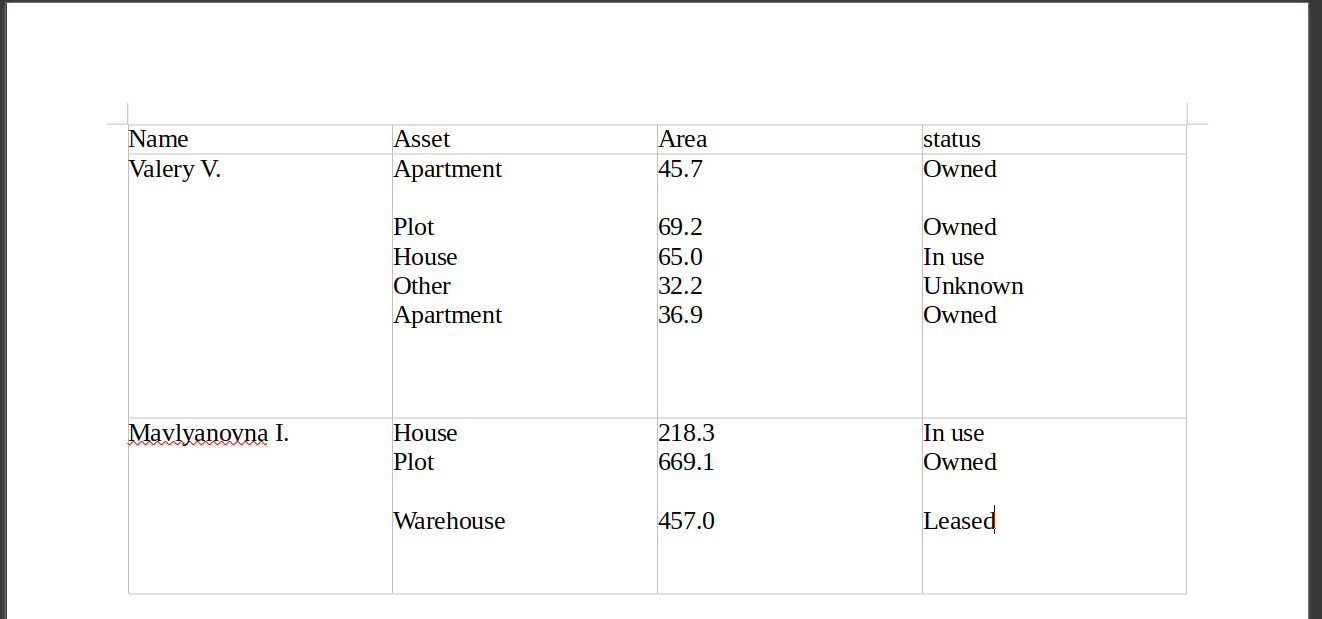
To replicate this example, the docx file is here, and the code below uses docxtractr to pull the contents of the table into R.
# necessary packages
library(docxtractr) # CRAN v0.6.5
library(dplyr) # CRAN v1.1.4
library(stringr) # CRAN v1.5.1
library(tidyr) # CRAN v1.3.1
library(unheadr) # CRAN v0.4.0
# path to downloaded Word file
docpath <- "New Sample/squishtest.docx"
sdoc <- read_docx(docpath)
dtable <- docx_extract_tbl(sdoc, header = TRUE, preserve = TRUE)To skip the download we could also recreate the output from docx_extract_tbl() stage with this code:
dtable <- data.frame(
stringsAsFactors = FALSE,
Name = c("Valery V.", "Mavlyanovna I."),
Asset = c("Apartment\n\nPlot\nHouse\nOther\nApartment",
"House\nPlot\n\nWarehouse\n\n"),
Area = c("45.7\n\n69.2\n65.0\n32.2\n36.9\n\n\n",
"218.3\n669.1\n\n457.0"),
Status = c("Owned\n\nOwned\nIn use\nUnknown\nOwned\n",
"In use\nOwned\n\nLeased")
)The output is ungainly, and everything that appears on separate lines within the borders of the ‘merged’ cells ends up together, separated only by line break sequences (\n).
> dtable
# A tibble: 2 × 4
Name Asset Area Status
<chr> <chr> <chr> <chr>
1 Valery V. "Apartment\n\nPlot\nHouse\nOther\nApartment" "45.7\n\n… "Owne…
2 Mavlyanovna I. "House\nPlot\n\nWarehouse\n\n" "218.3\n6… "In u…As a first step we can use the squish_newlines() function from unheadr to deduplicate and remove trailing line breaks, and because the rows in the initial table correspond to two different government officials, the operation is grouped using the .by argument.
dtable %>%
mutate(across(c(Asset:Status),squish_newlines),.by=Name) # A tibble: 2 × 4
Name Asset Area Status
<chr> <chr> <chr> <chr>
1 Valery V. "Apartment\nPlot\nHouse\nOther\nApartment" "45.7\n69.2… "Owne…
2 Mavlyanovna I. "House\nPlot\nWarehouse" "218.3\n669… "In u…Now we can separate the cell values into their own rows using separate_rows() from tidyr.
dtable %>%
mutate(across(c(Asset:Status),squish_newlines),.by=Name) %>%
tidyr::separate_rows(c(Asset:Status),sep="\n")# A tibble: 8 × 4
Name Asset Area Status
<chr> <chr> <chr> <chr>
1 Valery V. Apartment 45.7 Owned
2 Valery V. Plot 69.2 Owned
3 Valery V. House 65.0 In use
4 Valery V. Other 32.2 Unknown
5 Valery V. Apartment 36.9 Owned
6 Mavlyanovna I. House 218.3 In use
7 Mavlyanovna I. Plot 669.1 Owned
8 Mavlyanovna I. Warehouse 457.0 Leased Much nicer and ready for any number of operations. I hope this is helpful and as usual let me know if you run into any issues.