

Spreadsheet hijinks
Earlier in the week Jenny Bryan helped me ask the Twitter community what to call this widely used spreadsheet habit (see the image in my Tweet).
Do you have a pithy name for this spreadsheet phenomenon? Do tell! https://t.co/XbqOOSmr4i
— Jenny Bryan (@JennyBryan) September 10, 2018
I kept track of the replies to my tweet and to Jenny’s retweet, and here are most of the suggested names…
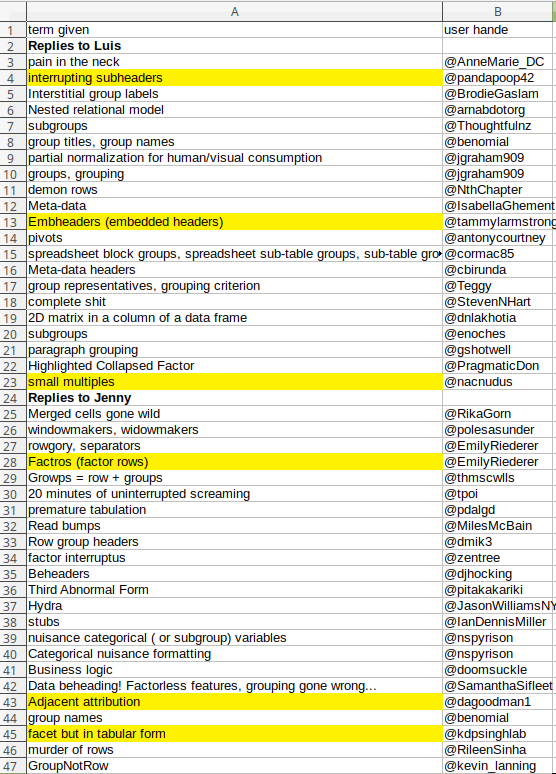
and again as a proper table…
| term given | user hande |
|---|---|
| Replies to Luis | NA |
| pain in the neck | @AnneMarie_DC |
| interrupting subheaders | @pandapoop42 |
| Interstitial group labels | @BrodieGaslam |
| Nested relational model | @arnabdotorg |
| subgroups | @Thoughtfulnz |
| group titles, group names | @benomial |
| partial normalization for human/visual consumption | @jgraham909 |
| groups, grouping | @jgraham909 |
| demon rows | @NthChapter |
| Meta-data | @IsabellaGhement |
| Embheaders (embedded headers) | @tammylarmstrong |
| pivots | @antonycourtney |
| spreadsheet block groups, spreadsheet sub-table groups, sub-table groups | @cormac85 |
| Meta-data headers | @cbirunda |
| group representatives, grouping criterion | @Teggy |
| complete shit | @StevenNHart |
| 2D matrix in a column of a data frame | @dnlakhotia |
| subgroups | @enoches |
| paragraph grouping | @gshotwell |
| Highlighted Collapsed Factor | @PragmaticDon |
| small multiples | @nacnudus |
| Replies to Jenny | NA |
| Merged cells gone wild | @RikaGorn |
| windowmakers, widowmakers | @polesasunder |
| rowgory, separators | @EmilyRiederer |
| Factros (factor rows) | @EmilyRiederer |
| Growps = row + groups | @thmscwlls |
| 20 minutes of uninterrupted screaming | @tpoi |
| premature tabulation | @pdalgd |
| Read bumps | @MilesMcBain |
| Row group headers | @dmik3 |
| factor interruptus | @zentree |
| Beheaders | @djhocking |
| Third Abnormal Form | @pitakakariki |
| Hydra | @JasonWilliamsNY |
| stubs | @IanDennisMiller |
| nuisance categorical (or subgroup) variables | @nspyrison |
| Categorical nuisance formatting | @nspyrison |
| Business logic | @doomsuckle |
| Data beheading! Factorless features, grouping gone wrong… | @SamanthaSifleet |
| Adjacent attribution | @dagoodman1 |
| group names | @benomial |
| facet but in tabular form | @kdpsinghlab |
| murder of rows | @RileenSinha |
| GroupNotRow | @kevin_lanning |
Overall, there seemed to be no clear-cut consensus but a few themes kept popping up, such as: groups, subgroups, headers, row groups, etc. Everyone is familiar with this somewhat annoying practice, and people from different disciplines pitched in with interpretations that often invoked concepts from database normalization or pivot tables.
Personally, I’m now partial to calling these things embedded subheaders. The header row typically contains the variable names, and the subheader concept seems more flexible. In this case they are embedded in the data rectangle to define subgroups or slices of data, equivalent to the small multiples concept from data visualization, as suggested by Duncan Garmonsway in his Spreadsheet Munging book.
I particularly liked adjacent attribution (suggested by Daniel Goodman) as a way to explain how embedded subheaders are expected to work. From what I could find out, this is a term from computer science used when defining clauses used to parse text strings. Embedded subheaders imply that the rows below them belong to a subgroup until a new subheader indicates otherwise, so establishing membership across different groups is a good example of attribution by adjaceny.
Lastly, I liked the name factros (factor rows) suggested by Emily Riederer, it has a cool tidyverse ring to it and I when I update the documentation for unheadr (an R package that can untangle most cases of embedded subheaders) with everyone’s feedback I will try to work it in.
If you have any other suggestions please let me know.