

Section lengths in scientific papers
Introduction
A few years ago, I was preparing a manuscript for submission to a journal and I received the following editing advice (from someone who had attended a writing workshop at some point):
Edit your manuscript to match the section length of recent papers in your target journal. This will standardize the overall format and subconsciously appease the reviewers and editors, potentially improving the chances of a favorable decision.
I found myself repeating this advice to other first-time manuscript submitters recently, and instead of letting them figure it out I went ahead and gathered some data to make this blog entry. This type of data should be of interest to authors, reviewers, and editors, all of whom deal with paper length and structure in one way or another.
Methods
I picked ten recent papers from five journals that I’m personally interested in, and counted the number of words in each of the sections (except for the references). These word counts don’t include table content or figure captions. I chose the 50 papers mostly at random (trying to include open access issues) and focused only on ‘standard’ articles that follow the traditional format for original research articles (unlike reviews or opinion pieces).
Here’s the code to download the raw data and recreate a rough version of the figure below.
Results
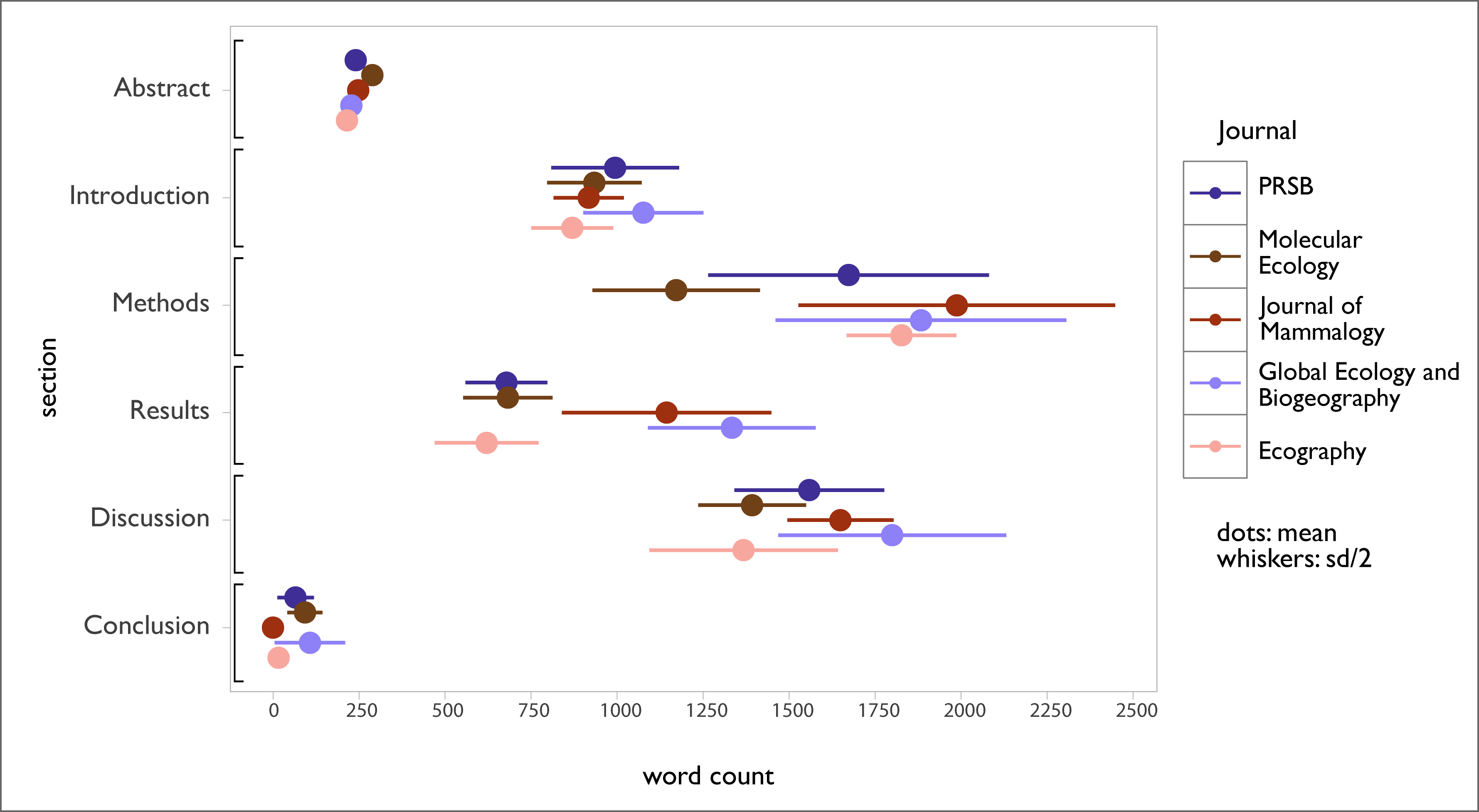
I used the palettetown package by Tim Lucas to get a color palette and I highly recommend it.
Discussion
Methods sections seem to be the lengthier parts of papers for most of the journals, although there is lots of variation and a fair amount of overlap with discussion sections. For some reason I always thought discussions were the longest parts of papers, but these data don’t agree. Introduction sections appear pretty consistent in length across journals.
I snuck a couple of my papers in there, and as much as I thought that I write concise and crisp papers, mine fell towards the lengthy end of the spectrum. In my defence, a lot of the bloat came during peer review - the early versions of the manuscripts did match the mean section lengths that I had calculated for initial submission.
I used a Chrome extension to count the words directly from each paper’s HTML view, the same format that could potentially be web-scraped, with the word counts automated by using the appropriate selectors. I tried to do this with rvest but failed; I’m still very new to scraping so if you think this is feasible let me know.
Concluding remarks
These are a small sample of papers from each journal, mostly because doing the word counts was very time-consuming. It should still serve as a guide if you’re submitting or reviewing for one of these journals